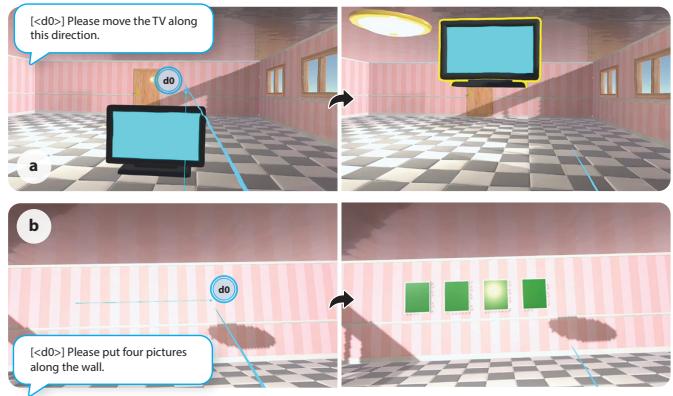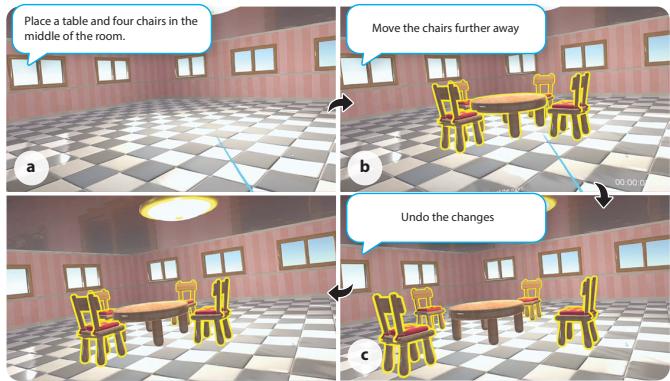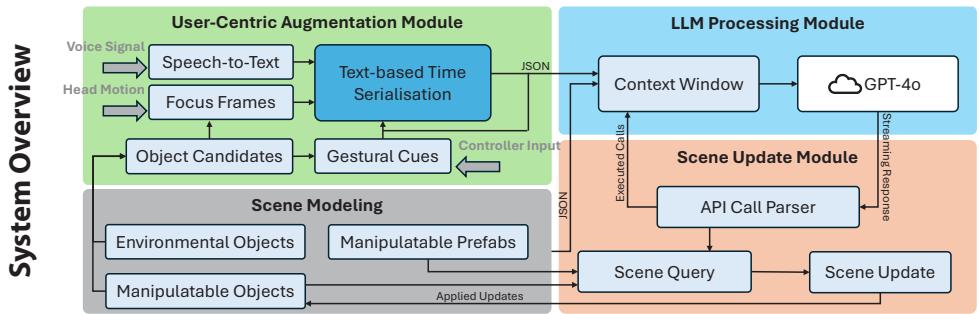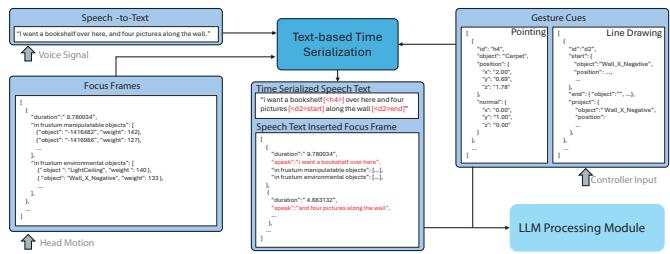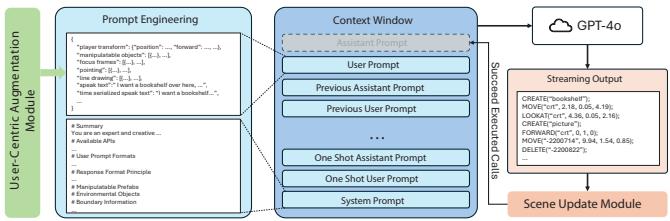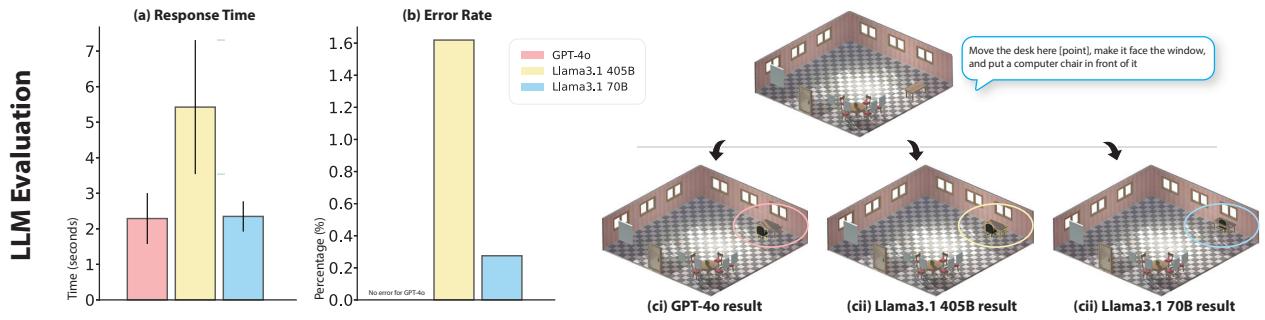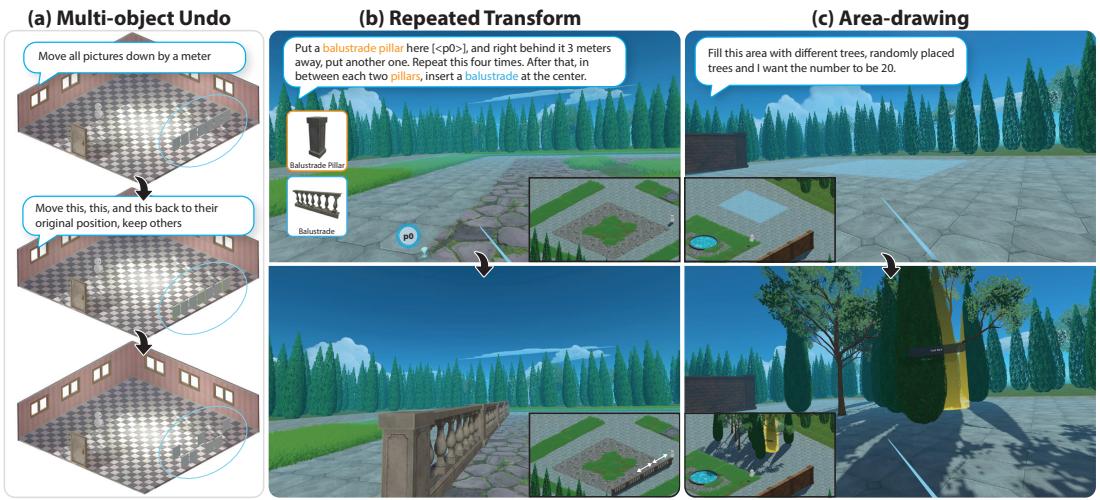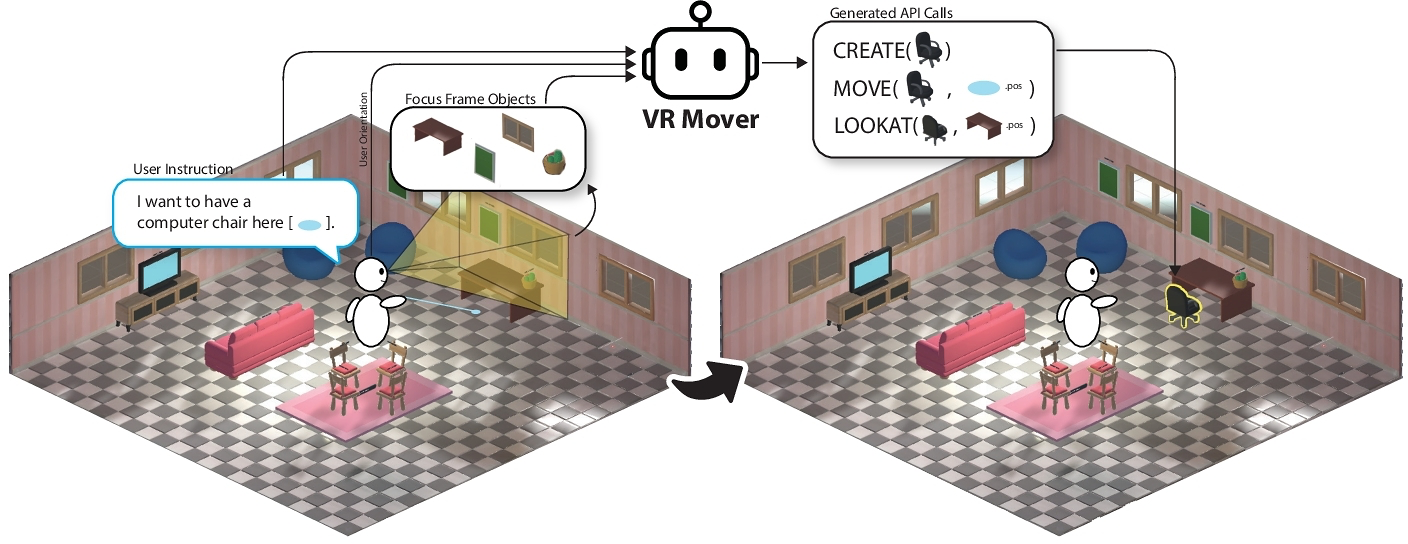
In our daily lives, we naturally convey instructions for spatially manipulating objects using words and gestures. Transposing this form of interaction into virtual reality (VR) object manipulation can be beneficial. We propose VR Mover, an LLM-empowered multimodal interface that can understand and interpret the user's vocal instructions combined with gestures to support object manipulation. By simply pointing and speaking, the user can command the LLM to manipulate objects without structured input.
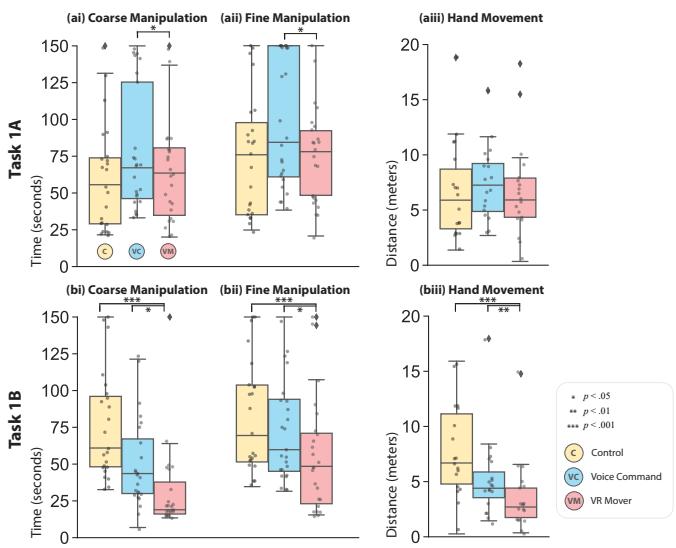
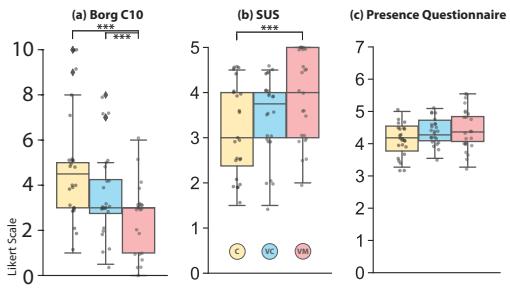
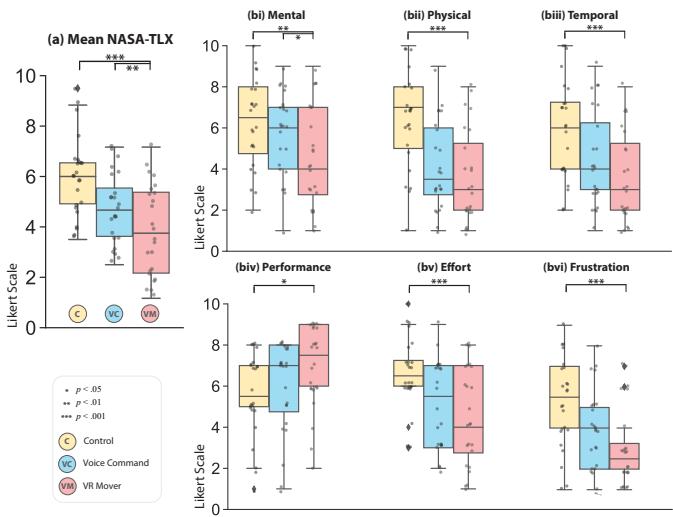
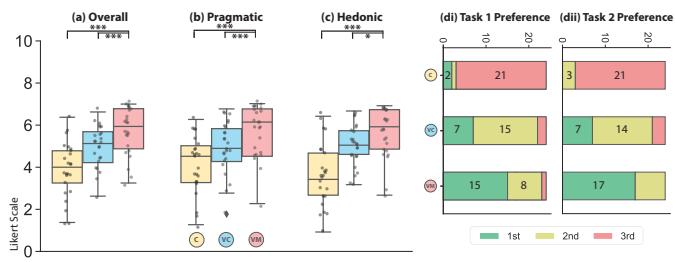
Compared to classic interfaces, our user study demonstrates that VR Mover enhances user usability, overall experience, and performance on multi-object manipulation, while also reducing workload and arm fatigue. Users prefer the proposed natural interface for broad movements and may complementarily switch to gizmos or virtual hands for finer adjustments. These findings are believed to contribute to design implications for future LLM-based object manipulation interfaces, highlighting the potential for more intuitive and efficient user interactions in VR environments.